
8 grudnia 2025 r. gościła w siedzibie PCSS delegacja z Ministerstwa...
Czytaj więcejKrajowy Magazyn Danych
infrastruktura dla składowania i udostępniania danych oraz efektywnego przetwarzania dużych wolumenów danych w modelach HPC, BigData i sztucznej inteligencji
Usługi
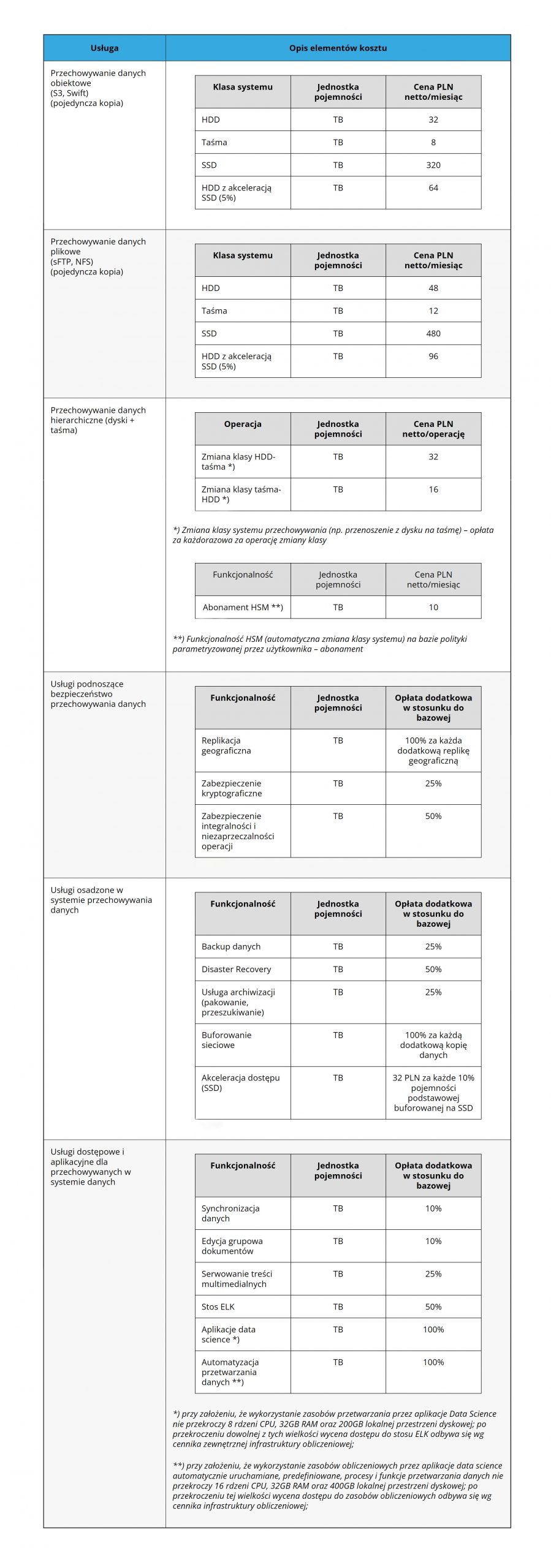
Składowanie danych
Obiektowe
Plikowe
Hierarchiczne
Niezawodne
Repozytoria danych
EOSC – otwarty dostęp
Kompatybilny z FAIR
Przetwarzanie danych niestrukturalnych
Bezpieczeństwo danych
Szyfrowanie danych
Repliki geograficzne
Niezawodne składowanie z redundancją
Analityka BIG DATA
Sztuczna inteligencja
Model Data Lake
Środowiska HPC i chmura
Przetwarzanie brzegowe
Usługi
Składowanie danych
Obiektowe
Plikowe
Hierarchiczne
Niezawodne
Bezpieczeństwo danych
Szyfrowanie danych
Repliki geograficzne
Niezawodne składowanie z redundancją
Analityka BIG DATA
Sztuczna inteligencja
Model Data Lake
Środowiska HPC i chmura
Przetwarzanie brzegowe
Repozytoria danych
EOSC – otwarty dostęp
Kompatybilny z FAIR
Przetwarzanie danych niestrukturalnych
O projekcie
Koncepcja KMD obejmuje fundamentalną przebudowę architektury do postaci otwartego, modularnego, rozszerzalnego oraz zdecentralizowanego i skalowalnego magazynu danych, wyposażonego w szereg interfejsów dostępowych oraz zintegrowanych usług i aplikacji, w tym mechanizmów wspomagających efektywne składowanie i dostęp do danych (wielopunktowa obsługa I/O, buforowanie), długoterminowe zarządzanie danymi, ich eksplorację, analizę i efektywne przetwarzanie.
Otwarta architektura systemu KMD zapewni możliwość dalszego rozszerzania funkcjonalności i dodawania kolejnych protokołów i interfejsów dostępowych do danych, np. usług prezentacji danych, usług do obróbki danych, aplikacji analitycznych czy mechanizmów integracji z systemami przetwarzania danych.
Usługi podstawowe systemu zapewnią możliwość przechowywania i zabezpieczania danych (fizycznego i logicznego), natomiast usługi dodatkowe, osadzone w systemie oraz usługi dostępowe umożliwią realizację zaawansowanych systemów, usług i aplikacji dano-centrycznych, w ramach których wymagane jest wydajne i bezpieczne składowanie, dostęp i przetwarzanie oraz zarządzanie dużymi i złożonymi wolumenami danych.
Technologie
- Przetwarzanie brzegowe (edge computing)
- Reguły dostępu FAIR, zgodność z EOSC
- Model Data Lake
- Elementy AI w analityce danych
Architektura
Infrastruktura
Celem bezpośrednim projektu jest opracowanie i dostarczenie produkcyjnych usług przechowywania, dostępu oraz zabezpieczania danych i zarządzania metadanymi a także integracji rozwiązań dla przetwarzania dużych i złożonych wolumenów danych na bazie rozproszonej infrastruktury. Umożliwi to integrację platform analitycznych oraz rozwiązań z zakresu uczenia maszynowego i sztucznej inteligencji w infrastrukturze danych i ścisłą integrację infrastruktury danych z systemami HPC i HTC w centrach HPC w celu efektywnego przetwarzanie obszernych i złożonych wolumenów i zbiorów danych.
Wskazana Infrastruktura KMD wraz z niezbędną regionalną i ogólnokrajową siecią wsparcia będzie tworzyć krajową platformę przechowywania danych i zostanie utworzona w powiązaniu z istniejącą w Polsce naukowo-badawczą infrastrukturą informatyczną. Utworzona przez konsorcjantów infrastruktura w terminie do końca 2024 podniesie pojemność infrastruktury przechowywania danych o 200 petabajtów oraz pojemność przestrzeni taśmowej o 180 petabajtów, a zastosowany przy jej budowie model Data Lake zapewni jej dużą elastyczność. Ponadto w wyniku projektu do 2024 udostępnione zostaną efektywne ekonomicznie usługi podstawowych procesów przechowywania i zarządzania danymi oraz ich przetwarzania i analityki. Więcej >
![842 [Converted]_ds_150ppi](https://kmd.pionier.net.pl/wp-content/uploads/elementor/thumbs/842-Converted_ds_150ppi-p9fapw8albu3kd40428b6ac8cd1rqx6thp5ez7snm0.png "842 [Converted]_ds_150ppi")
Partnerzy






Aktualności

Projekt KMD na ISC2025
Podczas targów ISC High Performance 2025 w Hamburgu (10–13 czerwca)...
Czytaj więcej
Piszą o nas: ElektronikaB2B
Portal ElektronikaB2B opublikował artykuł, na temat klasyfikacji systemu przechowywania...
Czytaj więcej
{kind=link}
System Lustre PCSS w pierwszej dziesiątce konkursu IO500 na konferencji SC24 w USA
W czasie konferencji Supercomputing 2024 w Altancie (USA) ogłoszone zostały...
Czytaj więcejKontakt
Lider projektu
Poznańskie Centrum Superkomputerowo-Sieciowe
ul. Jana Pawła II 10
61-139 Poznań
tel: (+48 61) 858 20 02